Как создать строку
Самый простой способ создать строку — это организовать ссылку типа
string
на строку-константу:
String si = "Это строка.";
Если константа длинная, можно записать ее в нескольких строках текстового редактора, связывая их операцией сцепления:
String s2 = "Это длинная строка, " +
"записанная в двух строках исходного текста";
Замечание
Не забывайте разницу между пустой строкой
string s = ""
, не содержащей ни одного символа, и пустой ссылкой
string s = null,
не указывающей ни на какую строку и не являющейся объектом.
Самый правильный способ создать объект с точки зрения ООП — это вызвать его конструктор в операции new. Класс string предоставляет вам девять конструкторов:
string()
— создается объект с пустой строкой;
string (String str)
— из одного объекта создается другой, поэтому этот конструктор используется редко;
string (StringBuf fer str)
— преобразованная коп-ия объекта класса
BufferString;
string(byte[] byteArray)
— объект создается из массива байтов byteArray;
String (char [] charArray)
— объект создается из массива
charArray
символов Unicode;
String (byte [] byteArray, int offset, int count)
— объект создается из части массива байтов byteArray, начинающейся с индекса
offset
и содержащей count байтов;
String (char [] charArray, int offset, int count)
— то же, но массив состоит из символов Unicode;
String(byte[] byteArray, String encoding)
— символы, записанные в массиве байтов, задаются в Unicode-строке, с учетом кодировки
encoding
;
String(byte[] byteArray, int offset, int count, String encoding)
— то же самое, но только для части массива.
При неправильном заданий индексов
offset
,
count
или кодировки
encoding
возникает исключительная ситуация.
Конструкторы, использующие массив байтов
byteArray
, предназначены для создания Unicode-строки из массива байтовых ASCII-кодировок символов. Такая ситуация возникает при чтении ASCII-файлов, извлечении информации из базы данных или при передаче информации по сети.
В самом простом случае компилятор для получения двухбайтовых символов Unicode добавит к каждому байту старший нулевой байт. Получится диапазон
' \u0000 ' — ' \u00ff '
кодировки Unicode, соответствующий кодам Latin 1. Тексты на кириллице будут выведены неправильно.
Если же на компьютере сделаны местные установки, как говорят на жаргоне "установлена локаль" (locale) (в MS Windows это выполняется утилитой Regional Options в окне
Control Panel
), то компилятор, прочитав эти установки, создаст символы Unicode, соответствующие местной кодовой странице. В русифицированном варианте MS Windows это обычно кодовая страница СР1251.
Если исходный массив с кириллическим ASCII-текстом был в кодировке СР1251, то строка Java будет создана правильно. Кириллица попадет в свой диапазон
'\u0400'—'\u04FF'
кодировки Unicode.
Но у кириллицы есть еще, по меньшей мере, четыре кодировки.
В MS-DOS применяется кодировка СР866.
В UNIX обычно применяется кодировка KOI8-R.
На компьютерах Apple Macintosh используется кодировка MacCyrillic.
Есть еще и международная кодировка кириллицы ISO8859-5;
Например, байт
11100011
(
0xЕ3
в шестнадцатеричной форме) в кодировке СР1251 представляет кириллическую букву
Г
, в кодировке СР866 — букву
У
, в кодировке KOI8-R — букву
Ц
, в ISO8859-5 — букву
у
, в MacCyrillic — букву
г
.
Если исходный кириллический ASCII-текст был в одной из этих кодировок, а местная кодировка СР1251, то Unicode-символы строки Java не будут соответствовать кириллице.
В этих случаях используются последние два конструктора, в которых параметром
encoding
указывается, какую кодовую таблицу использовать конструктору при создании строки.
Листинг 5.1 показывает различные случаи записи кириллического текста. В нем создаются три массива байто'в, содержащих слово "Россия" в трех кодировках.
Массив
byteCP1251
содержит слово "Россия" в кодировке СР1251.
Массив
byteСP866
содержит слово "Россия" в кодировке СР866.
Массив
byteKOI8R
содержит слово "Россия" в кодировке KOI8-R.
Из каждого массива создаются по три строки с использованием трех кодовых таблиц.
Кроме того, из массива символов
с[]
создается строка
s1
, из массива бай-тов, записанного в кодировке СР866, создается строка
s2
. Наконец, создается ссылка зз на строку-константу.
Листинг 5.1.
Создание кириллических строк
class StringTest{
public static void main(String[] args){
String winLikeWin = null, winLikeDOS = null, winLikeUNIX = null;
String dosLikeWin = null, dosLikeDOS = null, dosLikeUNIX = null;
String unixLikeWin = null, unixLikeDOS = null, unixLikeUNIX = null;
String msg = null;
byte[] byteCp!251 = {
(byte)0xD0, (byte)0xEE, (byte)0xFl,
(byte)0xFl, (byte)0xES, (byte)0xFF
};
byte[] byteCp866 = {
(byte)0x90, (byte)0xAE, (byte)0xE1,
(byte)0xEl, (byte)0xA8, (byte)0xEF
};
byte[] byteKOISR = (
(byte)0xF2, (byte)0xCF, (byte)0xD3,
(byte)0xD3, (byte)0xC9, (byte)0xDl
};
char[] с = {'Р', 'о', 'с', 'с', 'и', 'я'};
String s1 = new String(c);
String s2 = new String(byteCp866); // Для консоли MS Windows
String s3 = "Россия";
System.out.println();
try{
// Сообщение в Cp866 для вывода на консоль MS Windows.
msg = new String("\"Россия\" в ".getBytes("Ср866"), "Cpl251");
winLikeWin = new String(byteCp1251, "Cpl251"); //Правильно
winLikeDOS = new String(byteCpl251,: "Cp866");
winLikeUNIX - new String(byteCp1251, "KOI8-R");
dosLikeWin = new String(byteCp866, "Cpl251"); // Для консоли
dosLikeDOS = new String(byteCp866, "Cp866"); // Правильно
dosLikeUNIX = new String(byteCp866, "KOI8-R");
unixLikeWin = new String(byteKOISR, "Cpl251");
unixLikeDOS = new String(byteKOISR, "Cp866");
unixLikeUNIX = new String(byteKOISR, "KOI8-R"); // Правильно
System.out.print(msg + "Cpl251: ");
System.out.write(byteCp1251);
System.out.println();
System.out.print(msg + "Cp866 : ");
System, out.write (byteCp866} ;
System.out.println();
System.out.print(msg + "KOI8-R: ");
System.out.write(byteKOI8R);
{catch(Exception e)(
e.printStackTrace();
}
System.out.println();
System.out.println();
System.out.println(msg + "char array : " + s1);
System.out.println(msg + " default encoding : " + s2);
System.out.println(msg + "string constant : " + s3);
System.out.println();
System.out.println(msg + "Cp1251 -> Cp1251: " + winLikeWin);
System.out.println(msg + "Cp1251 -> Cp866 : " + winLikeDOS);
System.out.println(msg + "Cp1251 -> KOI8-R: " + winLikeUNIX);
System.out.println(msg + "Cp866 -> Cp1251: " + dosLikeWin);
System.out.println(msg + "Cp866 -> Cp866 : " + dosLikeDOS);
System.out.println(msg + "Cp866 -> KOI8-R: " + dosLikeUNIX);
System.out.println(msg + "KOI8-R -> Cpl251: " + unixLikeWin);
System.out.println(msg + "KOI8-R -> Cp866 : " + unixLikeDOS);
System.out.println(msg + "KOI8-R -> KOI8-R: " + unixLikeUNIX);
}
}
Все эти данные выводятся на консоль MS Windows 2000, как показано на рис. 5.1.
В первые три строки консоли выводятся массивы байтов
byteCP1251
,
byteCP866
и
byteKOI8R
без преобразования в Unicode. Это выполняется методом
write()
класса
FilterOutputStream
из пакета
java.io
.
В следующие три строки консоли выведены строки Java, полученные из массива символов
с[]
, массива
byteCP866
и строки-константы.
Следующие строки консоли содержат преобразованные массивы.
Вы видите, что на консоль правильно выводится только массив в кодировке СР866, записанный в строку с использованием кодовой таблицы СР1251.
В чем дело? Здесь свой вклад в проблему русификации вносит вывод потока символов на консоль или в файл.
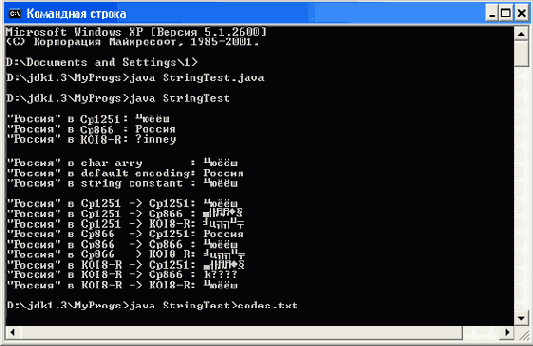
Рис. 5.1.
Вывод кириллической строки на консоль MS Windows 2000
Как уже упоминалось в
главе 1,
в консольное окно
Command Prompt
операционной системы MS Windows текст выводится в кодировке СР866.
Для того чтобы учесть это, слова "\"Россия\" в" преобразованы в массив байтов, содержащий символы в кодировке СР866, а затем переведены в строку
msg
.
В предпоследней строке рис. 5.1 сделано перенаправление вывода программы в файл
codes.txt
. В MS Windows 2000 вывод текста в файл происходит в кодировке СР1251. На рис. 5.2 показано содержимое файла
codes.txt
в окне программы Notepad.
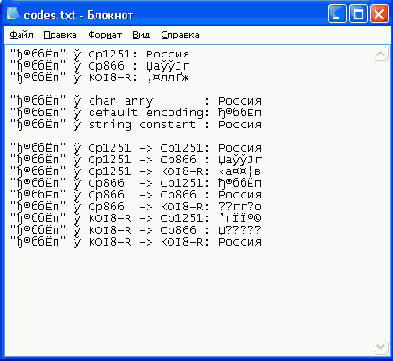
Рис. 5.2.
Вывод кириллической строки в файл
Как видите, кириллица выглядит совсем по-другому. Правильные символы Unicode кириллицы получаются, если использовать ту же кодовую таблицу, в которой записан исходный массив байтов.
Вопросы русификации мы еще будем обсуждать в
главах 9 и 18,
а пока заметьте, что при создании строки из массива байтов лучше указывать ту же самую кириллическую кодировку, в которой записан массив. Тогда вы получите строку Java с правильными символами Unicode.
При выводе же строки на консоль, в окно, в файл или при передаче по сети лучше преобразовать строку Java с символами Unicode по правилам вывода в нужное место.
Еще один способ создать строку — это использовать два статических метода
copyValueOf(chart] charArray)
и
copyValueOf(char[] charArray, int offset, int length).
Они создают строку по заданному массиву символов и возвращают ее в качестве результата своей работы. Например, после выполнения следующего фрагмента программы
chart] с = ('С', 'и', 'м', 'в', 'о
1
, 'л', 'ь', 'н', 'ы', 'й'};
String s1 = String.copyValueOf(с);
String s2 = String.copyValueOf(с, 3, 7);
получим в объекте
s1
строку "
Символьный
", а в объекте
s2
— строку "
вольный
".
